Collaborative Model in Interpreting Vague Descriptions in Situated Dialogue
Supported by Office of Naval Research (1/1/2011 - 12/31/2015)
Our perception of the environment often leads to the use of imprecise language, e.g., a tall building, a small cup, a car to the left, etc. While processing this kind of imprecise language may be less problematic to humans, interpreting imprecise language can be challenging to automated agents, especially in situated interaction. Although an artificial agent (e.g., robot) and its human partner are co-present in a shared environment, they have significantly mismatched perceptual capabilities (e.g., recognizing objects in the surroundings). Their knowledge and representation of the shared world are significantly different. When a shared perceptual basis is missing, grounding references, especially those vague language descriptions to the environment will be difficult. Therefore, a foremost question is to understand how partners with mismatched perceptual capabilities collaborate with each other to achieve referential grounding. This project has developed a simulated environment to address this question.
Here is an example of our experimental setup to study collaborations between conversation partners with mismatched visual perceptual capabilities
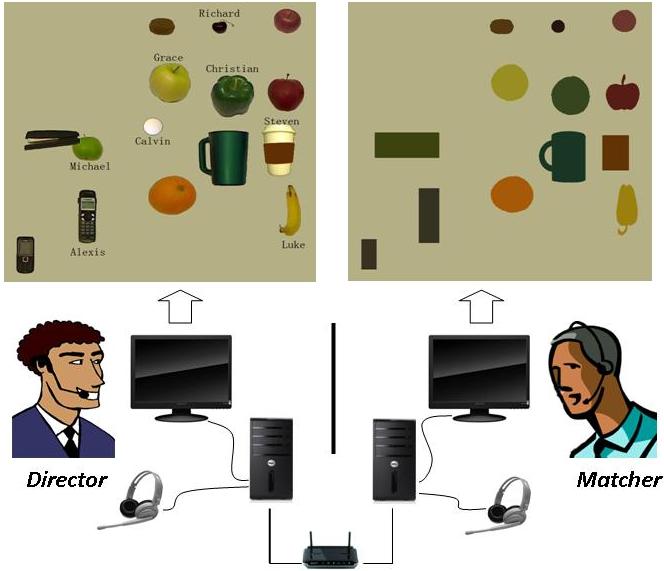
Related Videos:
Related Papers:
- Embodied Collaborative Referring Expression Generation in Situated Human-Robot Dialogue. R. Fang, M. Doering, and J. Y. Chai. Proceedings of the 10th ACM/IEEE Conference on Human-Robot Interaction (HRI), Portland, Oregon, March 2-5, 2015.
- Learning to Mediate Perceptual Differences in Situated Human-Robot Dialogue. C. Liu and J. Y. Chai. Proceedings of the 29th AAAI Conference on Artificial Intelligence (AAAI), Austin, Texas, January 25-30, 2015.
- Collaborative Models for Referring Expression Generation towards Situated Dialogue. R. Fang, M. Doering, and J. Y. Chai. Proceedings of the 28th AAAI Conference on Artificial Intelligence (AAAI), Quebec, Canada, August, 2014.
- Probabilistic Labeling for Efficient Referential Grounding based on Collaborative Discourse. C. Liu, L. She, R. Fang, and J. Y. Chai. Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics (ACL), Short Paper, Baltimore, MD, June 22-26, 2014.
- Collaborative Effort towards Common Ground in Situated Human-Robot Dialogue. J. Y. Chai, L. She, R. Fang, S. Ottarson, C. Littley, C. Liu, and K. Hanson. The 9th ACM/IEEE Conference on Human-Robot Interaction (HRI), Bielefeld, Germany, March 3-6, 2014.
- Towards Situated Dialogue: Revisiting Referring Expression Generation. R. Fang, C. Liu, L. She, and J. Y. Chai. Conference on Empirical Methods in Natural Language Processing (EMNLP), Seattle, WA, October, 2013.
- C. Liu, R. Fang, L. She, and J.Y. Chai. Modeling Collaborative Referring for Situated Referential Grounding. The 14th Annual SIGDIAL Meeting on Discourse and Dialogue (SIGDIAL), pp. 78-86, Metz, France, August, 2013.
- C. Liu, R. Fang and J. Y. Chai. Shared Gaze in Situated Referential Grounding: An Empirical Study. Book chapter in Eye Gaze in Intelligent User Interfaces. (eds.) Y. Nakano, C. Conati, and T. Bader. Springer, 2013.
- R. Fang, C. Liu, and J. Y. Chai. Integrating Word Acquisition and Referential Grounding towards Physical World Interaction. The 14th ACM International Conference on Multimodal Interactions (ICMI), Santa Monica, CA, October 22-26, 2012.
- C. Liu, R. Fang, and J. Y. Chai. Towards Mediating Shared Perceptual Basis in Situated Dialogue. The 13th Annual SIGDIAL Meeting on Discourse and Dialogue, Seoul, Korea, July 2012.